Kintsugi.
Published 19 February 2025 at Yours, Kewbish. 4,917 words. Subscribe via RSS.
Introduction
Last term, I wrote a couple of posts on cryptography concepts (on OPRFs and on Lagrange interpolation). In the conclusion of each of these posts, I’ve alluded to a new, related project that I’ve been working on this last term. That project is Kintsugi, and I’ve recently had the opportunity to present it at FOSDEM, widely regarded as the biggest open-source conference around. I realized that I’d never shared in-depth details about Kintsugi or how it works, and I thought I’d edit and republish my talk in article format. This post is a capstone to this series of crypto explainers, highlighting how we’ve combined ideas from both OPRFs and Lagrange interpolation to create a decentralized key recovery protocol for E2EE platforms.
Kintsugi’s elevator pitch goes as follows: Using E2EE apps mean that you’re solely responsible for keeping a copy of your keys, but what happens when you lose your device or backup files? E2EE apps like WhatsApp and Signal have recovery mechanisms, sure, but these schemes rely on one centralized provider that manages all the special hardware and servers that might be needed. Kintsugi is instead decentralized, based on a P2P network of recovery nodes. To recover your key, you use your password and communicate a threshold of your recovery nodes. Thanks to some fun crypto, though, these recovery nodes can’t brute-force access to your data offline, and even colluding recovery nodes can’t gain access to your account. Kintsugi doesn’t rely on all of these nodes being reachable, just a threshold of them, so it can remain operational even if some recovery nodes go offline. Kintsugi therefore lets you use a familiar password-based authentication scheme while retaining E2EE security properties and protecting against brute-force and recovery node collusion.1
This post will first cover some prior E2EE key recovery work, including the schemes that are used by the most popular E2EE apps today. If you’re impatient, you can skip through to the demo here. Then, I’ll detour into the basics of a couple cryptography primitives to recap this series’ prior two posts before covering the specific communication flows between recovery nodes. I’ll also add some of my hard-learned lessons from implementing Kintsugi in Rust with libp2p and Tauri.
If you’d prefer to watch through a video, you can find the recording here. The slides are also available here. Tab back over to the implementation details section after you’re done watching, since I don’t cover the actual system architecture or the P2P app architecture in much depth in my live talk.
Background Context

So, to contextualize the problem space a bit, let’s consider what happens when you lose your phone but want to regain access to data on some app you’d installed. With a non-E2EE app, you can just download the app again and log in with the same username and password. Your password can be checked against whatever the app server stores, and the server can return your data. However, if the app is E2EE, then this isn’t possible. The app server doesn’t store your password, recovery key, or anything to help you decrypt whatever encrypted backup data is stored on the server. There are a couple main recovery mechanisms: to name a few, you can set a recovery PIN, some apps let you designate a recovery contact, or you could store recovery codes or hard copies of recovery files.
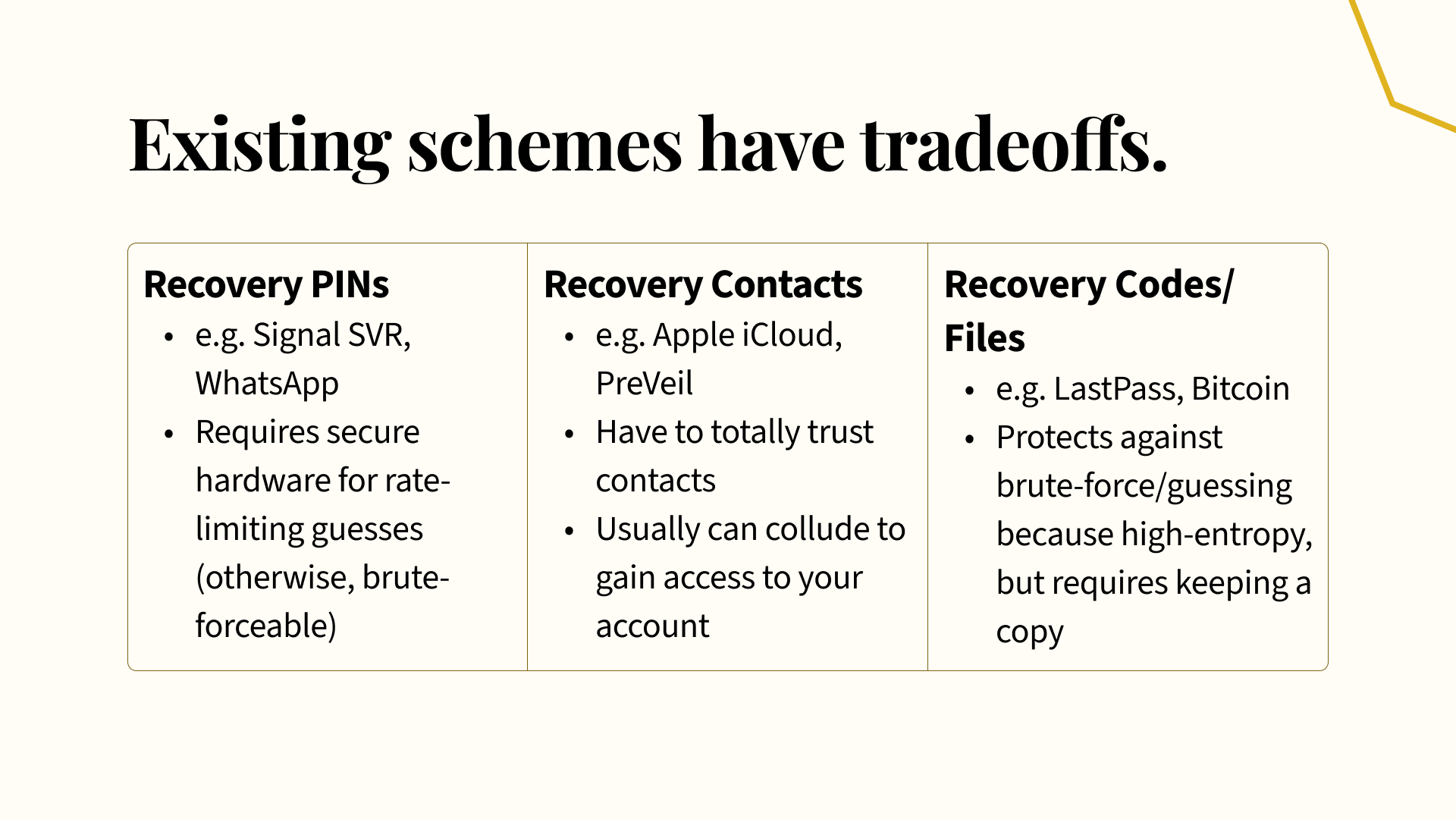
Unfortunately, these schemes each have tradeoffs. For example, Signal and WhatsApp both use some sort of PIN-based system for recovery. You set your account’s recovery PIN, a 4-to-6 digit code, from which a recovery key is derived and used to decrypt your backups. However, such a short code is easy to brute-force, so services must provide some form of rate-limiting. This usually relies on secure hardware, like hardware security modules, which will ensure that recovery attempts can only be performed once every so often. These HSMs are fairly expensive to run, though — Signal’s preprod system, with a very limited scale, cost over $2K a month to run — and can be difficult to deploy.
There are also recovery contacts, where you can designate a friend or a group of contacts, to help you recover your account. Apple iCloud is one such platform that lets you set up a recovery contact. The issue with social recovery schemes, though, is that you have to deeply trust your contacts. While, in some cases, you’ll have to provide some personal information during recovery, as iCloud requires, this is often guessable. On some platforms like PreVeil that enable groups of recovery contacts, a threshold of contacts are able to collude behind your back to reconstruct your recovery key in entirety without your input or knowledge. This isn’t good, as it essentially gives your recovery contacts all-powerful recovery access to your account (and remember that an account is only as secure as its least secure recovery option.)
Finally, some platforms like LastPass require you to store a set of recovery codes. Along the same lines, crypto wallets usually require you to store some seed phrase of 24 words or so, from which your private key is derived. These recovery codes are less prone to brute force concerns, since they’re longer and higher-entropy, so you don’t have to worry about expensive specialized hardware. On the other hand, this requires keeping a copy of the recovery codes or files around. Folks tend to misplace these, either digitally or physically, leading to total account lockout if you ever lose the files altogether. Also, because recovery codes are high-entropy and not as memorable as a password, it’s much more difficult to commit them to memory.

These recovery schemes also rely on some centralized app provider or source of trust, and this centralization comes with its own drawbacks. The model of a central authority controlling all the servers and hardware associated with an app simply doesn’t work for some contexts. For example, apps that require metadata privacy, like Tor, wouldn’t work well with an all-powerful, potentially-malicious provider. Other applications may be at risk of having their infrastructure shut down if they need to run everything on a single cloud provider, or perhaps the service lacks the concept of a responsible, central authority in the first place, as is the case with instance-based forums, for example. Infrastructure can also be cost-prohibitive, especially if the platform’s design requires specialized hardware, like the HSMs that Signal and WhatsApp use. Running these HSMs is complex and expensive, which limits the amount of decentralization possible — you can’t really use a volunteer-based operator model like Tor does if the hobbyist contributors can’t afford specialized hardware. Overall, while centralized recovery mechanisms work for existing apps, we wanted to explore a new space for recovery protocols in our research, particularly exploring schemes that were completely decentralized and didn’t require any specialized hardware.

This is where Kintsugi comes in! It’s a decentralized key recovery protocol based on a peer-to-peer network of recovery nodes. These nodes might be recovery servers run by different providers, end-user devices of social recovery contacts, like your friends, or a mix of the two. With Kintsugi, users recover their keys by providing their password and contacting some threshold t+1 of recovery nodes. These recovery nodes each store some share of a secret that’s needed to help the user reconstruct their key. Users can also update their recovery nodes at any time, which is something that’s ideal in a context where we plan to apply Kintsugi to, for example, recover access to a collaborative doc where you have changing collaborators. Kintsugi defends against brute force attacks on the password, malicious, colluding recovery nodes, and can remain operational with offline nodes.
Before I go further into how Kintsugi works, though, I wanted to go through a quick demo just so you can get a sense of what Kintsugi can help us do.
Demo
You can check out the implementation for this demo here. Kintsugi is implemented as a P2P app in Rust, with libp2p for the communication layer and Tauri with React for the demo app’s UI — more about this implementation later. This demo just shows the UI of the “user’s” node, but each Kintsugi node can serve as a recovery node for other Kintsugi nodes, and there’s no distinction between “users” and “recovery servers”.
In this video here, I walk through a user registering with a service that uses Kintsugi. Let’s say this service is an encrypted notepad service, and for simplicity, all you can do is read and write to a locally encrypted file. In this case, Kintsugi is used to protect the key used to encrypt this file.
- In the video, we first walk through registration. The user chooses their username and password, then configures their recovery nodes. The service can also do this opaquely in the background for the user. We’re just using a set of bootstrap nodes that I’m running separately in the background here.
- Then, we write to the encrypted notepad.
- Next, we delete the local login file to simulate device loss. This file holds the key that was used to encrypt the notepad, and is used for local login. So now, we no longer have a local copy of the key we need to decrypt the notepad.
- We then initiate recovery from our recovery node peers. The mapping from username to recovery nodes is stored in a distributed hash table that can be queried globally without knowing any particular recovery data. We then initiate a recovery request with our username and password, which starts communicating with our recovery nodes behind the scenes.
- Now, we can see that the keypair was successfully recovered and that we’re logged back in. As well, the notepad can now be decrypted, and we can read back what we wrote earlier. Finally, local login works again, since we’ve persisted our key locally again.
- We can also change the set of recovery nodes or the threshold for recovery and repeat the same recovery process. This is Kintsugi’s recovery node refresh flow.
Background Context, bis
(This section will duplicate content from the previous blog posts about OPRFs and Lagrange interpolation, but I’m keeping it in here because someone mentioned that the diagrams very clearly explained the math, and to be honest I’m still riding the high from the acknowledgement!)
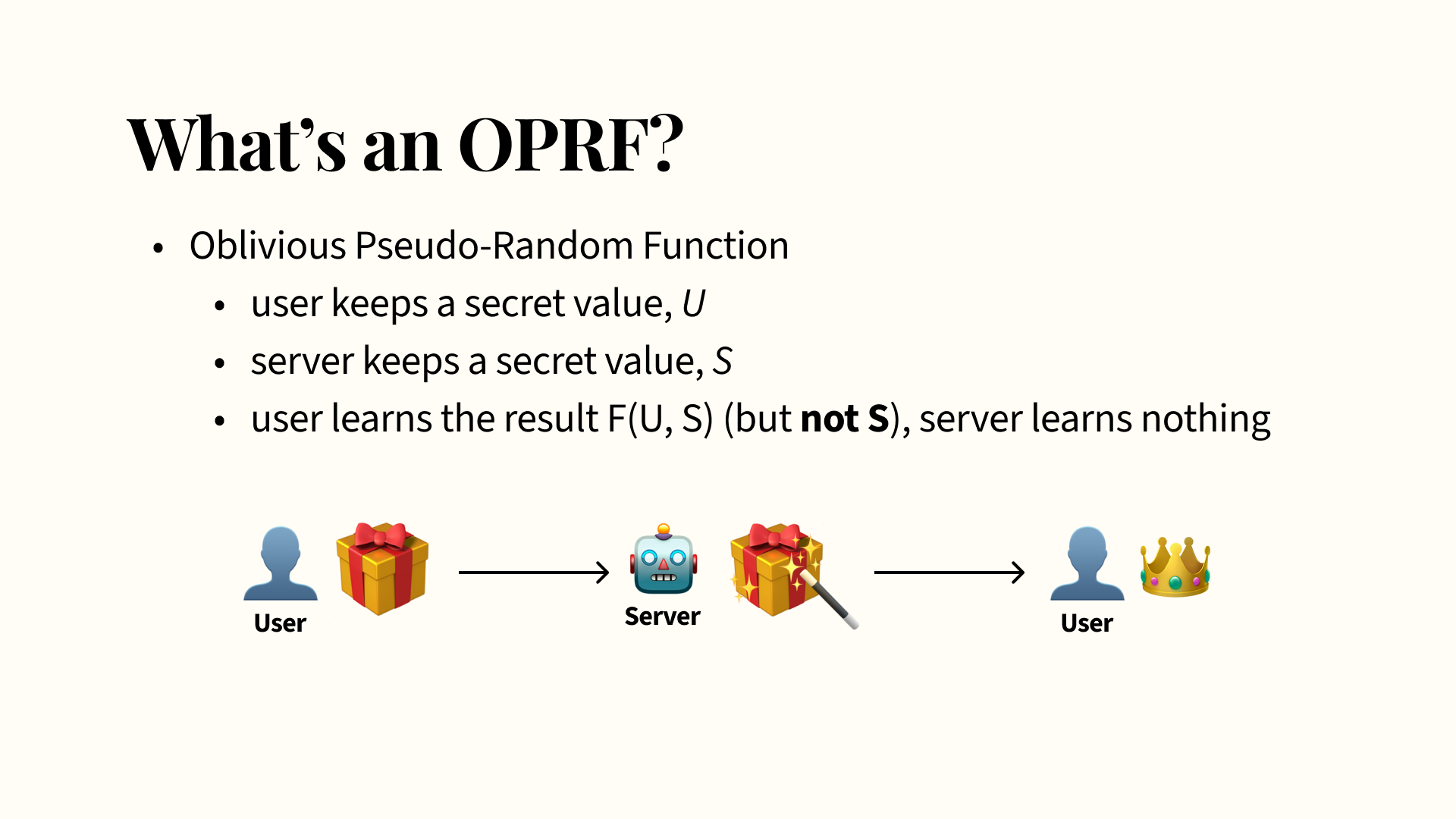
I’ll keep the crypto light to keep things accessible, but I wanted to briefly cover the basic concepts behind the main building blocks of Kintsugi here. For one, the cryptographic primitive we use to preserve E2EE properties and ensure that the recovery nodes can’t find out anything about the user’s password or final recovery key was via an Oblivious Pseudo-Random Function, or an OPRF.
An OPRF is a type of function where a user inputs a secret value, which we can call U, and their server inputs their own secret value, which we can call S. Evaluating an OPRF requires both the user and server to provide their secret values. However, only the user learns the function’s output, F(U, S), whereas the recovery nodes that participated don’t learn anything at all: specifically, not the output of the function. Neither party learns anything about the other’s secret value.
How does this work? The key is in what we call blinding. You can think of this as wrapping a secret present, like a top hat, in some wrapping paper. The user first blinds their secret value U before sending it to the server, so the server can’t actually see what U is. Then, the server operates on this blinded value — maybe think of this as some magic machine that transmutes the secret present into pure gold and gives it back to you. Then, you get to unwrap your present — unblind your output — and enjoy the end result. The server doesn’t see what your secret was, but you also don’t know metaphorically how the server turned your secret present into gold: by analogy, you don’t learn the server’s secret S during this evaluation either.
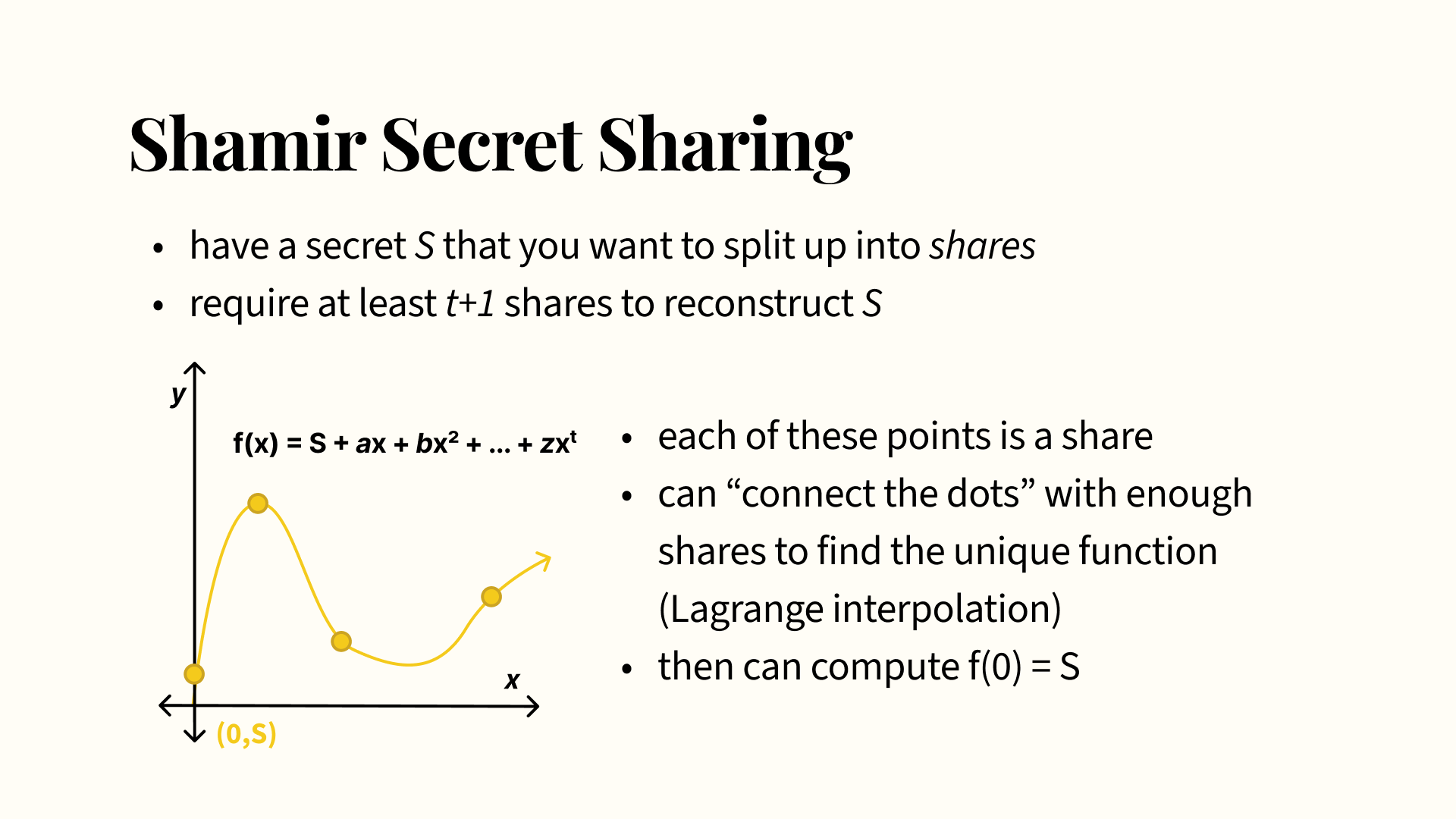
The other main concept used in Kintsugi is secret sharing. This is how we’re able to decentralize the key recovery and distribute trust across multiple recovery nodes. If you’ve heard of it before, we used an extension of the ideas in Shamir Secret Sharing (SSS). Forgive me if your eyes are glazing over at the sight of a polynomial on the slide, but I promise this is intuitive.
With SSS, there’s some secret S we want to split up into shares, and we want to make sure we require at least t+1 shares to reconstruct S.
Consider some function with a constant term of S. We can define some polynomial as the SSS polynomial as long as it passes through S at x = 0, so we’re able to choose these coefficients at random. We can then take points on the polynomial at different x values, which will be the secret shares. With a technique called Lagrange interpolation and given enough shares, you can “connect the dots” given by each of the points and eventually find the unique polynomial that passes through all of the shares. Then you can compute the function at x = 0 again, which gives you S. If a polynomial has t of these extra coefficient terms, then you have t variables, represented by a, b, and z, and so on, that you need to find the values of, and taking into consideration the extra S variable you need to also find, you need t+1 points in order to solve for these t+1 variables. The core TL;DR is that you take your secret S, draw some squiggly polynomial that goes through S, then take points on the curve that you can then connect back later to find your secret S again.

We used extensions of both OPRFs and Shamir Secret Sharing to actually build Kintsugi. In Kintsugi, we use threshold OPRFs, which are just like an OPRF, except that you have multiple servers, each with their own secret share. You send blinded requests to each of these servers, and you need to get a blinded execution back from t+1 of them to combine together before you unblind things to get your actual encryption key. This concept is explained in more detail in the TOPPSS paper by Jarecki et al.
As well, instead of Shamir Secret Sharing, we use a variant called dynamic, proactive secret sharing, where each recovery nodes’ secret values can be refreshed while keeping the overall shared secret S the same. This can be thought of as changing the points in the graph in the earlier slide, while keeping the overall value of S the same. We use dynamic, proactive secret sharing so the user can change their recovery nodes at any time — for example, if one becomes untrustworthy or goes permanently offline. Users can then make sure that old recovery nodes can’t participate in any new reconstruction efforts, while keeping the shared secret, later used to derive their recovery key, the same. This is described in the Long Live the Honey Badger paper by Das et al.
Registration
Now, let’s finally get into the three main flows you saw in the demo video: registration, recovery, and updating the recovery nodes.
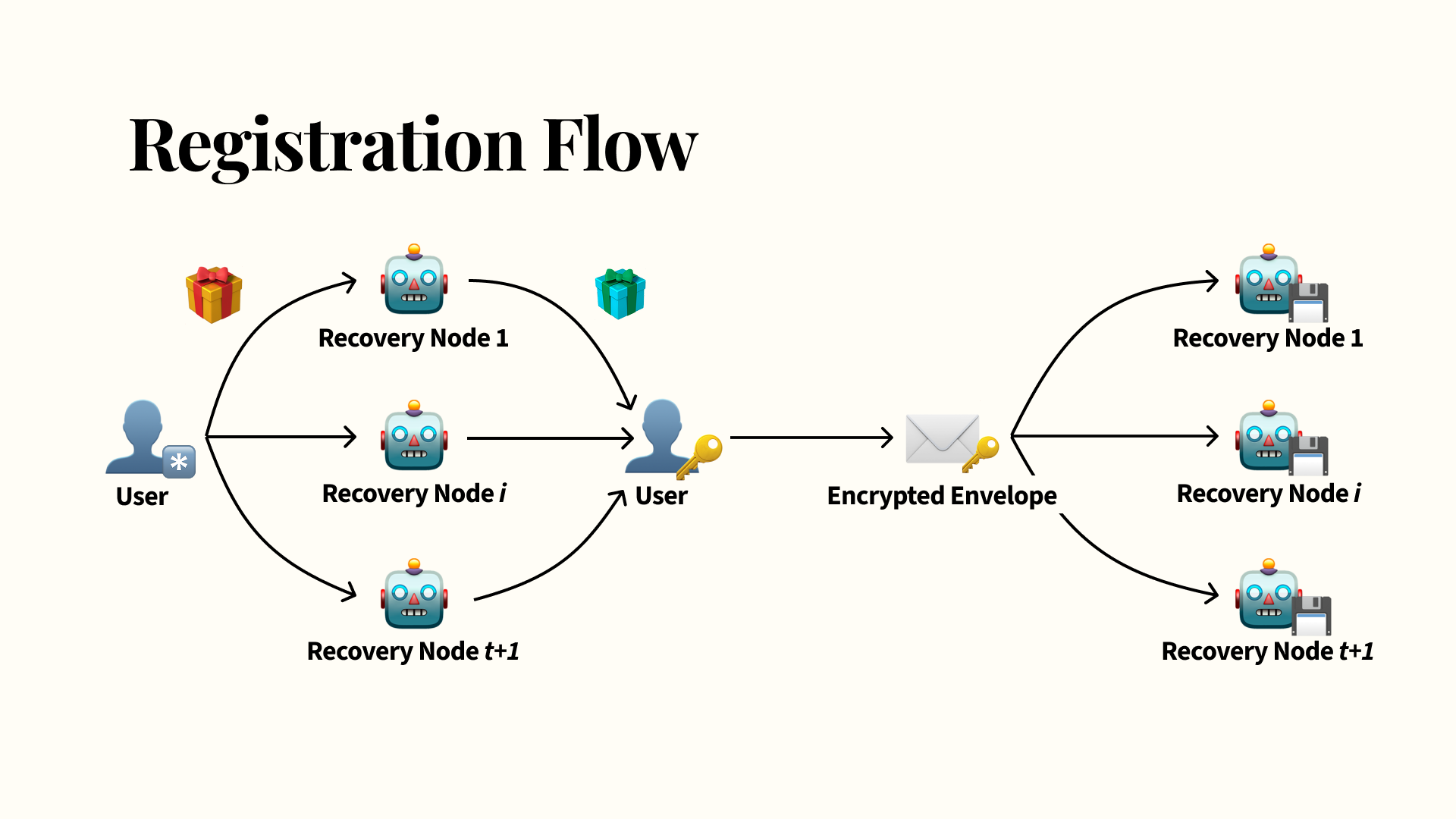
The first flow we saw in the demo is registration: users start with their password, which they blind. Recall that blinding is an operation that’s easy for the user to perform and undo but that the server can’t break, which prevents the recovery nodes from finding out the user’s password. Users send this blinded password (represented by the yellow present) to their recovery nodes. Users need to get responses from at least t+1 recovery nodes, where this t is a threshold that the user can choose during registration. Each of these t+1 recovery nodes hold a share of a recovery secret. Note that you don’t have to reach out to all of your recovery nodes during this process, so if some of them are down during registration that’s fine.
The user takes the blinded password and combines it with the node’s secret share via a threshold OPRF, represented by the blue present. Remember how I mentioned with threshold OPRFs, the other parties don’t learn anything about the user’s password or the final output, which only the user sees? In this case, the user takes the final output, unblinds it, and uses the OPRF evaluation result as another key. This OPRF result key is used to encrypt their recovery key and any recovery data they want to save. The blinding and the threshold-based communication here prevent the recovery nodes from mounting an offline brute-force attack. We call this encrypted backup the encrypted envelope, which is sent to the recovery nodes to be persisted.
Recovery
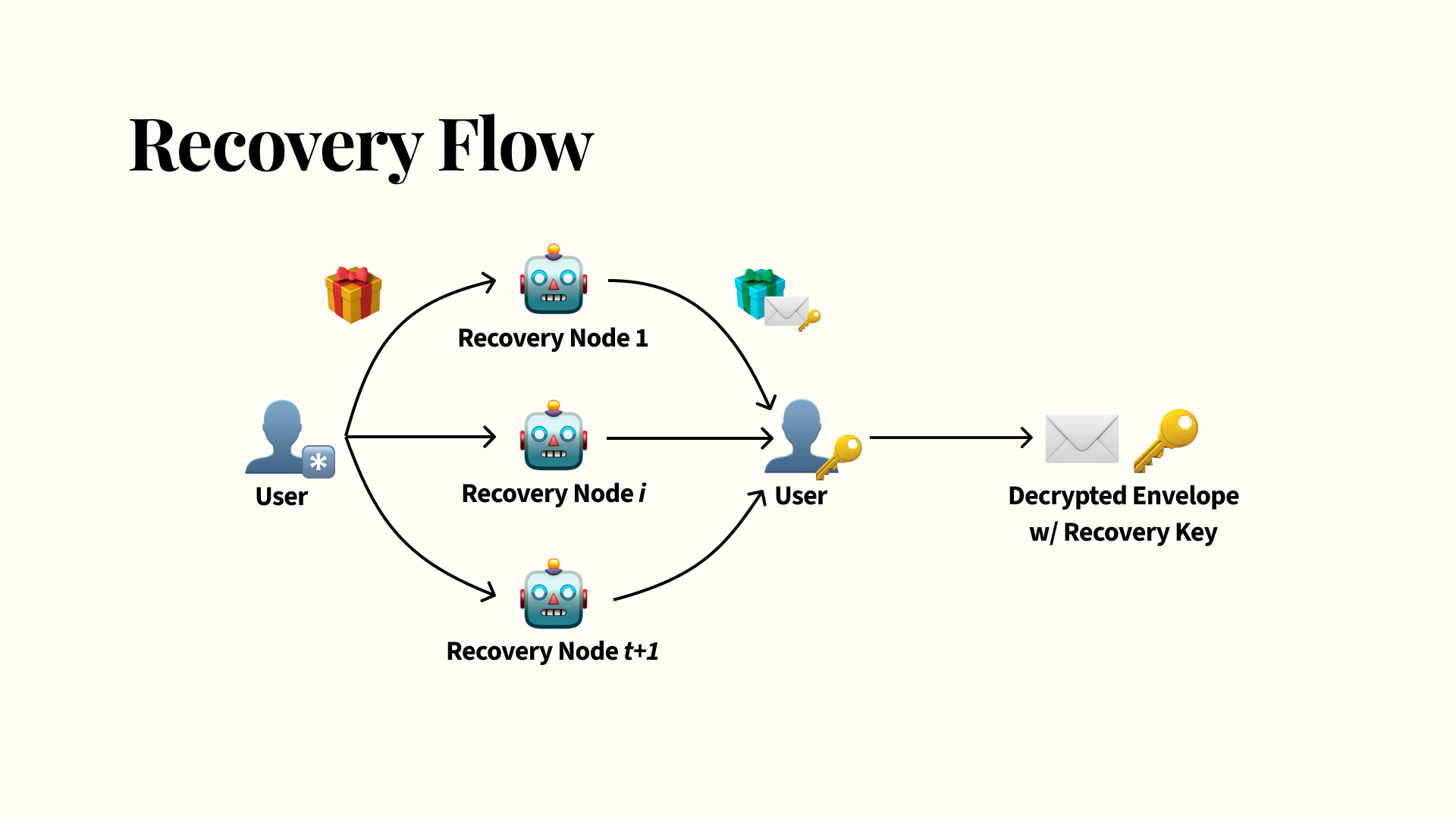
During recovery, the user performs a similar exchange: they blind their password and send it to the recovery nodes. Again, you don’t have to reach all of your recovery nodes, just a threshold, so if some nodes are offline you can still proceed with recovery. The recovery nodes each combine the blinded password with their respective shares and return their blind OPRF evaluations to the user along with the encrypted envelope that they’ve stored. The user reconstructs their encryption key via the returned OPRF evaluations and with Lagrange interpolation, and decrypts the encrypted envelope to get their recovery key back.
These nodes also perform rate-limiting as an additional layer of brute-force protection without requiring any secure hardware. Because you need to wait for a threshold of nodes to return results before you can attempt to reconstruct the key, you’re limited by the slowest recovery node. As long as one recovery node correctly implements a recovery attempt rate limit (which we assume in our threat model), the attempts will be rate-limited overall as well. This gets you some nice decentralized rate limiting as a result.
Also, because no single recovery node has the whole recovery secret, you’ll need a whole threshold of at least t+1 nodes to collude in order to get access to the shared recovery secret. Even then, these colluding nodes must still perform a brute-force attack, since the user’s password was blinded, so they can’t directly decrypt the encrypted envelope that they’ve persisted. This provides protection against colluding recovery nodes.
Refreshing Update Nodes
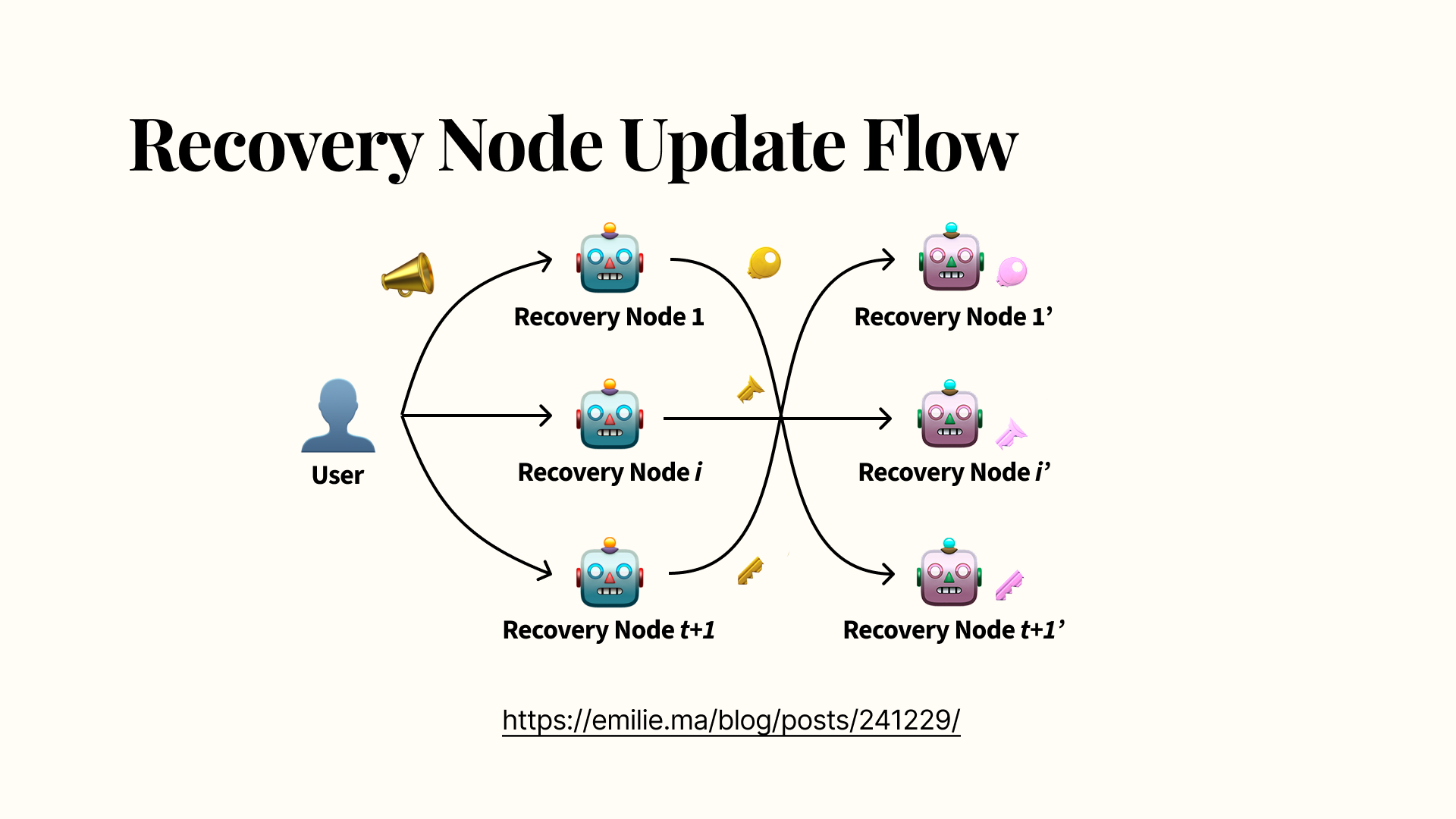
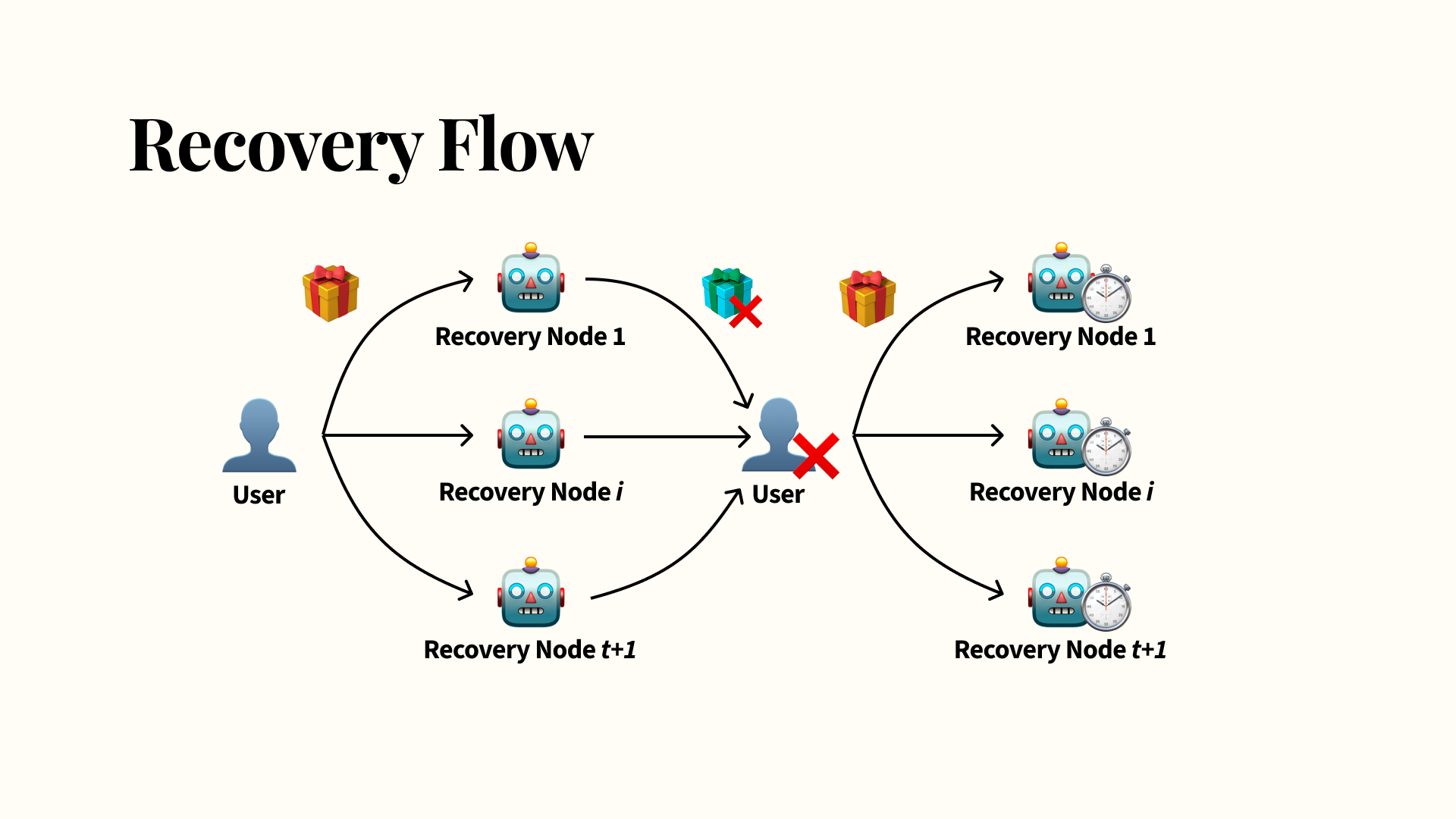
If the user wishes to update their recovery nodes, they send a notification to the old recovery nodes. A threshold of the old recovery nodes then use dynamic, proactive secret sharing to refresh their shares, communicating second-order shares of shares to the new recovery nodes (represented by the pink robots). These new recovery nodes might overlap with the old recovery nodes significantly, or indeed be the same set of nodes, or be completely different. The new recovery nodes reconstruct their new shares with Lagrange interpolation, which are then used from this point onwards.
Intuitively, consider that the original secret is split into shares once at each of the original, blue recovery nodes. Each of those shares is split up again in the second step in passing on shares to the new recovery nodes (pink robots). This broadcast just changes which pink robots hold which sub-shares of the original secret, but the underlying shared recovery secret remains the same. If you’re interested, I wrote a blog post that explains dynamic proactive secret sharing more, but let’s wrap up all this math and take a look at the concrete implementation instead.
Implementation Details
Kintsugi is written in Rust, and the GitHub repository is available here under the MIT License. The P2P communication builds on the libp2p framework, primarily based on the request-response module. libp2p is used by the likes of Ethereum, IPFS, and Filecoin, to name a few. You can read more about its basic model here and see the Rust tutorial here. The gist of libp2p is that it’s structured as an event-based loop, with everything from peer discovery to actual protocol messages implemented as so-called NetworkBehaviours that can define event handlers.
The client UI was developed with the Tauri framework, using React as a frontend framework for familiarity’s sake. Tauri lets you invoke commands, which are defined in Rust, from JS, and likewise emit events, which are handled in JS, from Rust. Tauri requires you to restructure your Rust and web frontend a little: for example, it needed to hold all the mutable state, and it needed to get the right same async runtime plugged in. There were few resources with using it with another async library like libp2p — I found this blog post very helpful for figuring out how to wire libp2p and Tauri together.
The event loop has to be written as a separate future to be managed by the Tauri app handle, and Tauri and libp2p have to be connected via a separate mpsc::channel. Here’s the general architecture:
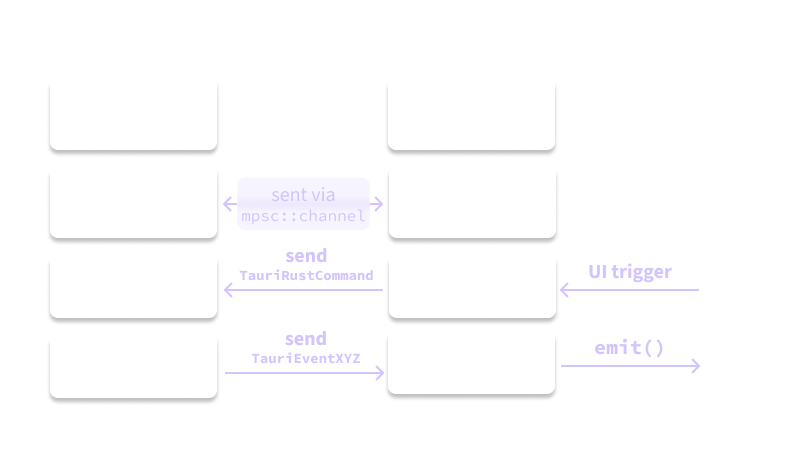
You can see this event loop here. For UI events, the commands that are invoked by the Tauri JS side forward extra messages through the mpsc::channel to initiate libp2p requests. There’s a receiver here in the event loop that takes in messages from this channel. You need to forward messages via this channel due to how Tauri is managing node state and where the libp2p communication objects are available, scope-wise. Specifically, the #[tauri::command] commands have to take in all parameters from the UI on the JS side, so it doesn’t have access to libp2p components. All these commands are responsible for is sending a message to . These libp2p messages are processed here and here, sending responses back or kicking off yet more requests.
We initially started building Kintsugi with the gossipsub module, but there were some issues with gossipsub reporting InsufficientPeers even when there were multiple recovery nodes subscribed to a topic as well as problems with topic re-creation that blocked development. Someone mentioned in the comments that it might have just been an issue with the crate tagging, but I didn’t verify if this was the fix since I’d already begrudgingly ported everything to the request-response module already anyways. The request-response model worked better with our final design anyways, since the user individually blinds their password for each recovery node and since the recovery nodes only want to communicate directly with the user instead of broadcasting message information around willy-nilly.
Peer discovery is handled by the mDNS module, and for now only takes place on the local network. For distributing global information like the user to recovery node mapping, we use the built-in Kademlia DHT module. We had to add some record verification to check signatures and the well-formedness of messages (here), but the Kademlia module’s event-based structure led to some very annoying callback hell and required a lot of state to be passed around (example). If you want to enable message filtering, for message verification, for instance, you have to write event listeners both for the first attempted write to the DHT as well as the filtering request that has to perform the actual write. This complicated event structure was one of my main frustrations with libp2p. It’s likely because I don’t come from an event-driven programming background, but I found the model to lead to convoluted code that was hard to visualize without drawing out an explicit data flow graph.
There were also limited examples for what I needed references for (e.g. a very stripped down Kademlia basic example without peer discovery), although the docs and existing example apps were mostly enough to piece things together. I also hadn’t gotten much experience with async Rust beforehand, so there was an extra learning curve on top of the framework details, even after going through the Async Rust handbook.
One very nice thing about libp2p was that the network communication (at least over a local network, I didn’t mess with any NAT hole-punching) worked flawlessly. As I was explaining my libp2p woes to someone one day, they mentioned that with P2P networks, it’s usually always the network that causes issues. I’m happy to report this wasn’t the case at all. This was fairly surprising, since I was developing on eduroam for most of the project, and I’d expect there’s plenty of firewalling and broadcast limitations implemented.
Some other implementation notes:
- I wouldn’t recommend integrating Tauri with all the libp2p events in one fell swoop. Instead, I’d suggest starting from a smaller example and adding on only when the basic communication is working, since this limits the amount of refactoring you need to do if something all goes wrong (e.g. if you need to switch
NetworkBehaviours). This sounds very intuitive, but it’s very tempting to build out all the libp2p communication, then just slap Tauri on top, but it took ages to debug. - Sometimes when libp2p messages don’t seem to be getting sent properly, check if you have a mutex deadlock somewhere, particularly if you’re also letting Tauri manage your shared node state with an
Arc<Mutex<T>>or something similar. - It was easy to overlook in the docs for async commands, but make sure the Tauri app handler has its async runtime set properly (here).
- Migrating to Tauri’s minor idiosyncrasies with all the annotations, and the event-based loop that libp2p required, gave the project a natural tendency towards putting all the code in one file so various callbacks would be in one place and there wouldn’t be any scoping or visibility issues. At one point, my
main.rswas some >2K LoC, which was still tenable but unsustainable for explaining the project to anyone. It was more straightforward to refactor than expected, but again I’d advise starting with a more logically separated crate structure from the get-go.
Overall, libp2p took some time to get used to, particularly when integrating it with Tauri, but the event-loop-based approach is starting to grow on me as I’m becoming more comfortable debugging issues. If I were to reimplement Kintsugi, I’d be happy going with this stack again.
Conclusion
So that’s been a whirlwind walkthrough of Kintsugi: I’ve walked through some of the reasons why existing E2EE key recovery methods are lacking, gone through some fun intros to crypto, and finally touched on how Kintsugi works. With Kintsugi, our main improvement over existing recovery methods is our focus on decentralization. We also don’t require any expensive hardware, can tolerate device loss, provide brute-force resistance, and protect against colluding recovery nodes. Here’s the “money slide” conclusion from the talk:

Kintsugi is currently perhaps on a bit of a pause. I’ve finished the protocol demo that you can see on GitHub, after much libp2p wrangling and a frantic grind towards getting the demo fully functional for FOSDEM. After I wrapped up the MVP demo, I ended up needing to focus on moving to my next internship and prepping for the FOSDEM talk, and have since not had much time to make progress. There’s still plenty to look forward to in the future though: I should really continue polishing up the implementation, as there’s plenty of (noncritical) loose ends like Byzantine value agreeemtn that I haven’t fully implemented yet. There’ve also been some vague discussions of integration with the Ink & Switch decentralized access control project Beehive, and I’ve gotten some other messages from and chatted with folks interested in potentially using Kintsugi’s theory in their own E2E platforms.
Speaking of getting questions and emails, I’m reminded of something my UBC supervisor said the last time I gave a talk, about how it’s nice to take academic research to industry conferences, both since it encourages you to ensure your work can be repackaged and massaged into something that’s immediately impactful to real developers, and for reaching a new audience beyond at-times stuffy academia with different considerations and goals. Getting to think through these questions is a nice side effect of the opportunity and a very-much-appreciated affirmation that my work matters in some small way. It’s also unique feedback that helps you better think through and articulate the project in the future. For example, I got a couple reoccurring questions about what happens if some recovery nodes are down, or if not all the initial recovery nodes are reachable upon registration, so I’ve tried to do a better job in this blog post to reiterate that only a threshold of nodes need to be reached.
I’ll be presenting Kintsugi again at the International Workshop on Security Protocols in March, and the proceedings should be available not long after then. I’ve set a reminder to update this post with a link to the paper once it’s out, as it explains some of the finer-grained details with more nuance and clearer caveats. Leaving this as a placeholder here until I’ve put it up — you can also feel free to subscribe to notifications on this GitHub issue, as I’ve also set a reminder to comment there once I can upload a version of the paper to the repo.
That’s about it from Kintsugi for now, but I’m also writing up my FOSDEM experience in a separate post. I only attended for the first day, but I’ll still be touching on some of the other talks I attended and some “survival tips” in the vein of these posts. If you’re less concerned with cryptography and more interested in treasure hunts, tangents about trip planning, and survival guides, look forward to that being out next week!