A Year of Articles.
Published 26 December 2021 at Yours, Kewbish. 2,505 words. Subscribe via RSS.
This post is unlisted and has been archived. This doesn't represent my best work; please check out the posts listed here instead.
Introduction
Early in January this year, I had a bit of a realization I was spending too much time reading blog posts. That, combined with a typical New-Year’s resolution-y mood, resulted in me tracking every single article I read that month. I’d been reading a bit about the whole Quantified Self community, and thought that while I wouldn’t go as hardcore with collecting data on myself, I’d take a stab at recording and rationalizing my leisure content consumption. Armed with a shabbily-patched-together Chrome extension and a hacky Google Form, I sorted out a system where I’d hit a keybind to record the URL and timestamp of any post I was reading. This experiment mostly aimed to give me a sense of what my reading habits were like, and give me a fun data visualization at the end. Well, I guess my muscle memory of hitting Alt-T every time I stumbled across anything interesting on Twitter persisted, because I ended up continuing this experiment for the whole year.
I wrote out a more comprehensive list of ‘rules’ in the January blog post, but the gist of it was that: I wouldn’t include forum sites, programming help, quick Googles for one-off topics. I would, on the other hand, include the jumping-off points of deeper rabbit holes, any long and short form articles, and a new addition to the criteria - sometimes also lengthy / interesting Twitter feeds. Data was collected with my custom Chrome extension (source not available, but it just programmatically pushes to a central Google Forms - more about this was in the January post). For today’s analysis, I pulled all the article information I had from the very beginning of this year (~6 January) to about the 20th of December. I’d say that’s a pretty good spread of data, and I think we’ll be able to capture some interesting trends that I already expect. Last year, I talked a lot about information aesthetics, and I think that applied even more so this year. I know I had less time to read starting in the fall, so I gravitated more heavily towards existing sources of cool writing and avoided more exploration.
So, without further ado - I present to you, A Year Of Articles; or, as I like to call it, Kewbish Wrapped.
The Hypotheses
As all good experiments do, I started by considering some of my hypotheses. In January, I’d found that towards the end of the month, I ended up reading less (which was sort of my goal back then - I wanted to reduce mindless clicking and content consumption). With regards to time, I usually had a couple big spikes in reading during the very beginning and ends of my day. I also found that I tended to read more on weekends - reasonable, as I usually had lots more time to scroll HN or Lobste.rs on the weekends. I liked that I was able to build up a notetaking system and a library around what content I’d read, and also that I’d be able to find interesting articles that I’d picked up over the last month.
Over the past year’s data, I expected I’d keep finding most of these trends. Most of the above findings, I reasoned, would apply until at least summer, which was when I kind of both fell off tracking and started reading more casual articles (i.e. ones I didn’t track) a bit more. Around September, I started really dialling in instead on optimizing my learning workflow for university, and really didn’t have the time to read much anymore. My Matter1 backlog started growing quite a bit, which I suppose would speak to the fact that it’s easy to use, and became my consumption ‘source of truth’. That’s good, and what I intended. However, I just wasn’t finding the time to regularly process it, and I remember that starting a bit of a feedback loop of intimidation of going through it. As such, I probably expect that around the beginning of the school year - when I remember my backlog starting to pile up - there’d be a sharp decrease in reading.
I won’t be discussing each and every URL I read the past year here, but in terms of more meta-analysis, I expect to see a bunch more articles about tools for thought, planning, and meta-productivity in general. I still expect that my content ‘diet’, as people apparently put it, will be largely composed of the same Twitter-adjacent people I follow: tools for thought leaders, indie makers, and a rather niche subset of the larger SWE industry.
The Data
In total, in 2021 (minus a week or so in December), I read 535 articles. (174 of these were from the initial January experiment). That averages out to 1.54 articles a day - a rather reasonable number, and roughly what I expected given my binge-reading during the beginning of the year and my lack of reading towards the latter half. This graph shows the spread of the articles over the day of the year, with a rolling three-day average:

Figure 1. Articles read per day.
You can see a very sharp spike near the beginning of the experiment in January - my running average then was about 6.69 articles per day, according to my previous writeup. The reading activity sort of bottoms out around around June and July, where the articles read a day became more consistent (when averaged). As I expected, and as I observed in January, there’s still obvious spikes within each month, which I expect are from my weekend reading sprees. I’m sort of surprised that come August and September, I tended to read more articles than in the early summer, even though I’d have expected that I was spending more time adapting to university work. This ‘second spike’ might have lined up when I started to write brief summary notes again on the articles I’d read - a habit that didn’t quite continue through to October or November.
I also crunched the time data for each article read and came up with a graph showing the most frequent times I’d read articles:
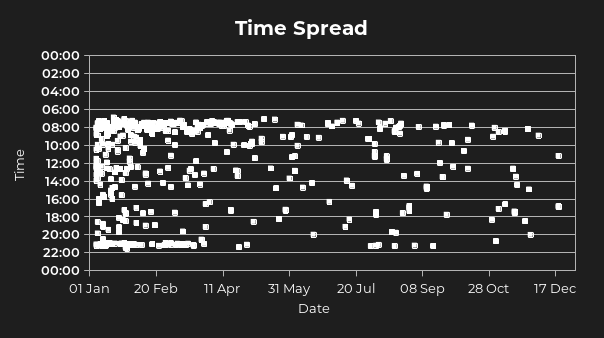
Figure 2. Time distribution for article readings per day.
In the beginning of the graph, you can see a very heavy trend of morning reading sometime between 0800-0900. This persisted, though to a lessening extent, throughout the year. There’s also a decently frequent trend of night-time reading around 2000-2100, which stopped somewhere in mid-March, according to the graph. I think this graph shows some of the changes in my reading habits well: during the beginning of the year, after the initial January spike, I was quite systematic and rigorous about what I was reading and when. Through the summer and into the school year, however, I ended up fitting articles in during my breaks and other in-between time, so there’s not as clear of a trend later in the year.
I also thought it’d be interesting to briefly look at the most frequent websites that I read from. The most frequently read URLs and their number of occurences were:
- thesephist.com, at 16 articles
- paulgraham.com, at 13 articles
- every.to, at 11 articles
- lesswrong.com, at 8 articles
- ben-evans.com, at 7 articles
- bulletjournal.com, at 5 articles
- nesslabs.com, at 5 articles
- evantravers.com, at 4 articles
Medium and Nitter links weren’t included in the above, though they rounded out to 8 articles each. I also did a bit of manual checking to get rid of the unique-URL problem with Paul Graham’s blog, where I was somehow tracking both www and non-www versions of the URL. There were lots of other creators in the list with 2-3 posts each as well, but those were my top 10 URLs. I’m pretty unsurprised with this list: I would have likely been able to name at least the larger blogs in this list. It’s actually interesting to note that the majority of the list (not listed) has only 1-2 posts, reflecting a more indie / niche posting streak that I didn’t return to as frequently.
The Findings
I think the trend that I overall spent much less time reading throughout the year is very obvious, but I’d like to dive into a couple possibilities besides ‘school stress; no time’ that could have contributed to that. One, Findka, a now defunct service that worked to automatically crowdsource recommendations for essays and articles to read, shut down sometime early this year. I shouldn’t say shut down - just pivoted to their new work with email newsletters instead (more about that later). Previously, before using Findka, I’d relied on the front page of HN or CS Reddits or Twitter communities. With Findka, I was able to pretty consistently find interesting new content, without doing much searching myself. As Findka’s recommendations died down, I simply didn’t have many recommendations for articles to read, and the friction of going to find new ones just to satisfy my article cravings was too much. Two, I started shifting the time that I’d previously allocated to reading long or short-form articles towards exploring communities and individuals on Twitter. I started using Nitter much more, and I think that this new stream of information somewhat replaced what I was getting from Findka. As a result, I ended up consuming more short-form tweets and exploring thoughts there. Of course, I didn’t track individual tweets, just occasionally long threads that I’d come across, but this is what I’d suspect from what I remember over the past year.
I don’t feel like there’s anything really to change about these reading habits. I’d like to perhaps dedicate more time in the coming year to read long-form articles and tackle some of the backlog that’s built up over finals season again. One of my main blockers was that I didn’t have easy access to my backlog while on my phone or anywhere not on my laptop: Matter tracks everything through a GitHub issue system, and I’m usually not logged in on mobile. Maybe a feature I’ll start working on is a custom URL just for me that links to my GitHub token and would let me access my backlog through Matter when on mobile, but there’re some security things that I’d probably want to iron out better before I go live with that. Being able to spend too much more time on reading is probably wishful thinking, but hopefully since I’ll keep it mind more I’ll also end up doing it more.
Some other changes I’d like to consider next year are expanding my content sources a bit, with regards to both creators and in topic. Right now, as you can see with my top few URLs, I end up returning to the same couple creators and the same few areas of content: productivity, HCI, and theoretical CS if I feel intellectual. It might be nice to move away from overall content aggregators like HN or Lobste.rs, and revisit Findka’s new offering of a newsletter forwarder called The Sample. I found that Findka gave me a decently nice breadth of articles that were all tailored to my general preferences for voice, tone, and topic. One of my friends is working on something really cool in this recommendation / discovery space as well, and I’ve been pestering them every so often to see what their work’s looking like. Another system I’m following is Paul Bricman’s Lexiscore, which aims to combat information overload and tweak your digital content ‘diet’. Tools like that provide content that’s more immediately interesting to me, and I end up spending less time scrolling endlessly looking for interesting things. I’m cognizant of possible echo chamber effects if I rely too heavily on recommenders that are tuned directly to my liking, but if I only have so much time for reading, I may as well enjoy it.
And lastly, I had a system early in the year where I’d pull all the articles from my reading tracker at the end of each week and briefly summarize it. I’d built up a list til about the middle of the year of annotated links - noting anything interesting about the post, specific quotes or lines that I thought were interesting, or keywords that I might be able to link to when chatting with friends about similar topics. I ended up not doing that over the latter half of the year, mainly due to time constraints again. If possible, I think that annotation process made my reading a lot more active and meaningful, so I’d like to get back into it. I liked looking back over a week’s worth of reading and seeing what I tended towards and what interesting ideas others had around me, so perhaps I’ll pick this up again in the New Year.
Conclusion
I think this was a pretty fun self-experiment to run over the past year, so I’ll likely refresh my spreadsheet and form architecture and run it again next year as well. It’s like a Year In Review retrospective that some developers do crossed with the data analysis and whimsy of Spotify Wrapped. I personally like meta-analysis content like this, so look forward to the possibility of a Kewbish Wrapped 2022 late next year. And while today, I mostly discussed the consumption of content, I’ll be writing up a post about my content creation processes and how those have changed sometime in February2.
I’m writing this late on Christmas Day, so happy holidays, for those of you who are reading. I’m excited to finally have a break from formal, structured school, and some time for myself to tinker around with some dev stuff as well as pre-read for the next term. I’m still waiting for some of my grades to come out, which isn’t particularly fun, but I think I’ve mentally disengaged with my grades, at least for this term. What’s done is done, and I may as well focus on how I can make the next term as efficient and satisfying as possible instead. I’ve finally finished up AOC earlier today, so I plan to use that chunk of time that I’d previously dedicated to bodging my way through solutions each morning to maybe doing some more writing. I enjoy sitting here and brain-dumping all of the musings I have sometimes, so hopefully I’ll have some more articles and thoughts to share in the New Year.
-
The tool I use to track all my ’to-reads’ and RSS feeds, more about it here. ↩︎
-
The first blog post ever on YK was published on Valentine’s Day around two years ago - this was mostly a personal joke à la ‘haha look at me I’m so lonely and nerdy that I wrote about my open source instead of touching grass and having fun what a cs kid’. But I think that time of year’s actually a bit better for retrospective / new-year’s content, since by then any resolutions you’ve stuck to have had enough time to sink in and develop, and any that you haven’t managed to keep up have long been ditched. ↩︎